




À propos du client
Notre client fournit des solutions d’IA et de data science à partir de données en temps réel. Il accompagne les entreprises manufacturières en proposant des services d’ingénierie des données, de machine learning et de développement d’applications Aveva PI. Notre client est expert dans la transformation de données brutes et non structurées en opportunités commerciales génératrices de revenus pour ses clients finaux, avec l’appui de nos partenaires SEEQ et Aveva.
L’entreprise avec laquelle nous avons collaboré dispose d’une vaste expérience industrielle, associée à une forte présence dans le secteur de l’énergie. Elle intervient auprès de nombreuses grandes entreprises américaines et internationales de production d’électricité ainsi que du secteur pétrole et gaz, et propose un large éventail de services dans ces secteurs et au-delà.
Défi Commercial
Dans l’industrie pétrolière et gazière (celle dans laquelle opère le client final), quelques secondes de dysfonctionnement d’un système peuvent entraîner de graves conséquences opérationnelles, de sécurité et financières. Le client final était confronté à plusieurs problèmes au sein de son paysage de données existant, qui limitaient la fiabilité, la scalabilité et une gestion efficace des changements.
Les principaux défis techniques et de livraison comprenaient:
- Plusieurs systèmes de référence (SOR) mal synchronisés, chacun avec son propre modèle de données
- Des workflows centrés sur les documents (PDF, feuilles de calcul, papier) au lieu de processus structurés et centrés sur les données
- Une clôture lente des demandes de changement, des mises à jour manquantes et des incohérences croissantes entre les SOR
- Des exigences changeantes et évolutives, en particulier aux premières étapes de la définition de la solution
- La nécessité de concevoir des preuves de concept à partir de données fictives et d’une ontologie simplifiée, puis de les affiner en un modèle de données de niveau production
- L’adoption d’une nouvelle stack technologique (modélisation d’ontologies, graphes de connaissances, AVEVA AF) sans expérience préalable de l’équipe
- Une dépendance à des experts côté client pour des composants hautement spécialisés (p. ex. pilotes/« drivers » AVEVA AF)
- Des délais de communication et de feedback côté client, impactant la planification et la vitesse d’itération
Processus
Le projet a été livré grâce à une collaboration étroite et fréquente avec le client. Cela a inclus des ateliers de découverte et des sessions d’alignement afin de clarifier les objectifs et les exigences, ainsi que des réunions régulières de synchronisation organisées jusqu’à trois fois par semaine. Des stand-ups quotidiens ont été mis en place lorsque nécessaire pour maintenir la dynamique. Afin de soutenir une compréhension approfondie du domaine et la qualité des données, un ingénieur dédié a été intégré spécifiquement pour l’analyse des données du client final, garantissant une interprétation précise des données source et une progression plus rapide lors des phases de découverte et de développement.
Phase 1 – Découverte et définition des exigences
Inclut: collecte, clarification et documentation des exigences
Phase 2 – Développement
Inclut: développement logiciel principal et mise en œuvre du système
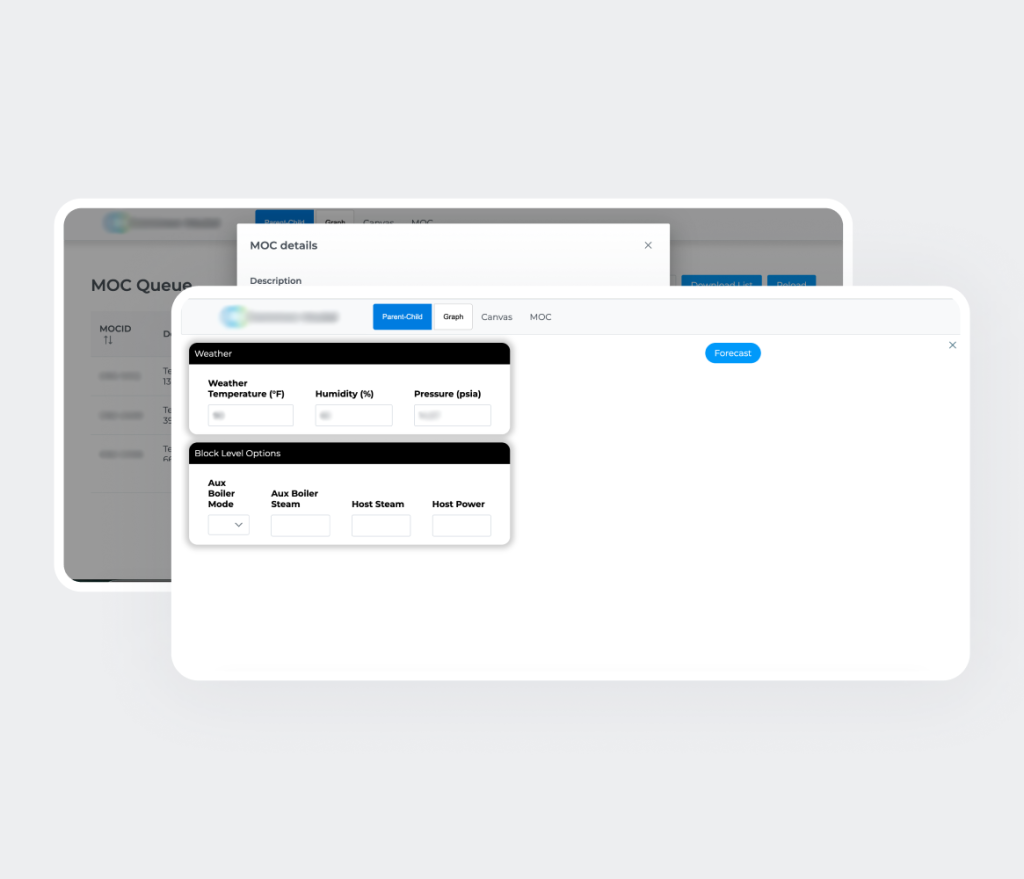
Phase 3 – Capacités étendues (prévue)
Périmètre: développements supplémentaires, notamment des fonctionnalités de simulation et des améliorations de la validation MOC
Échéance: 10 mois
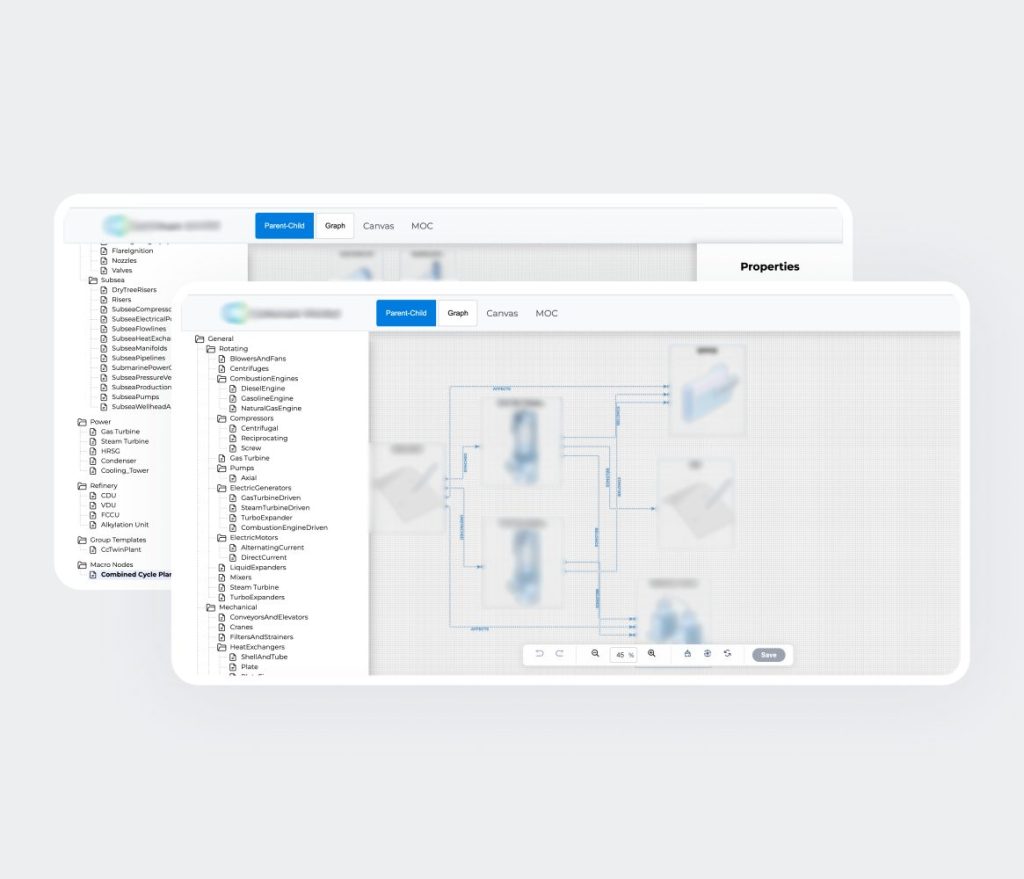
Aperçu du Produit Final
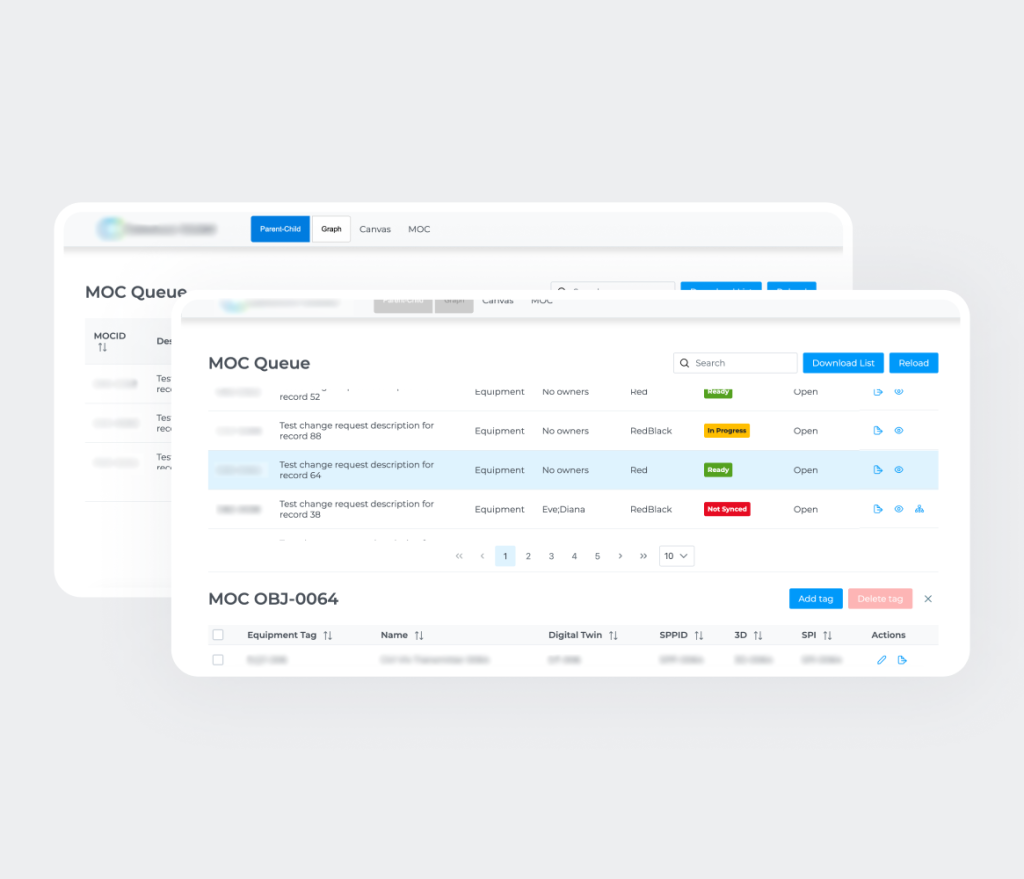
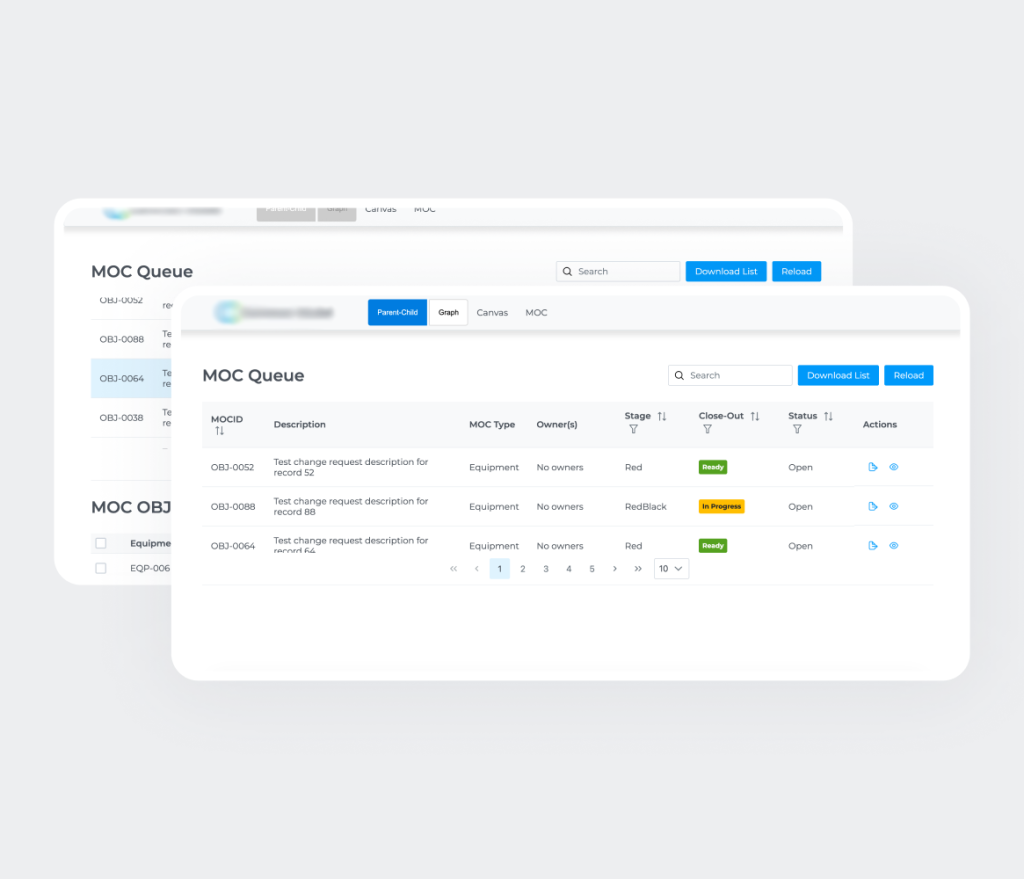
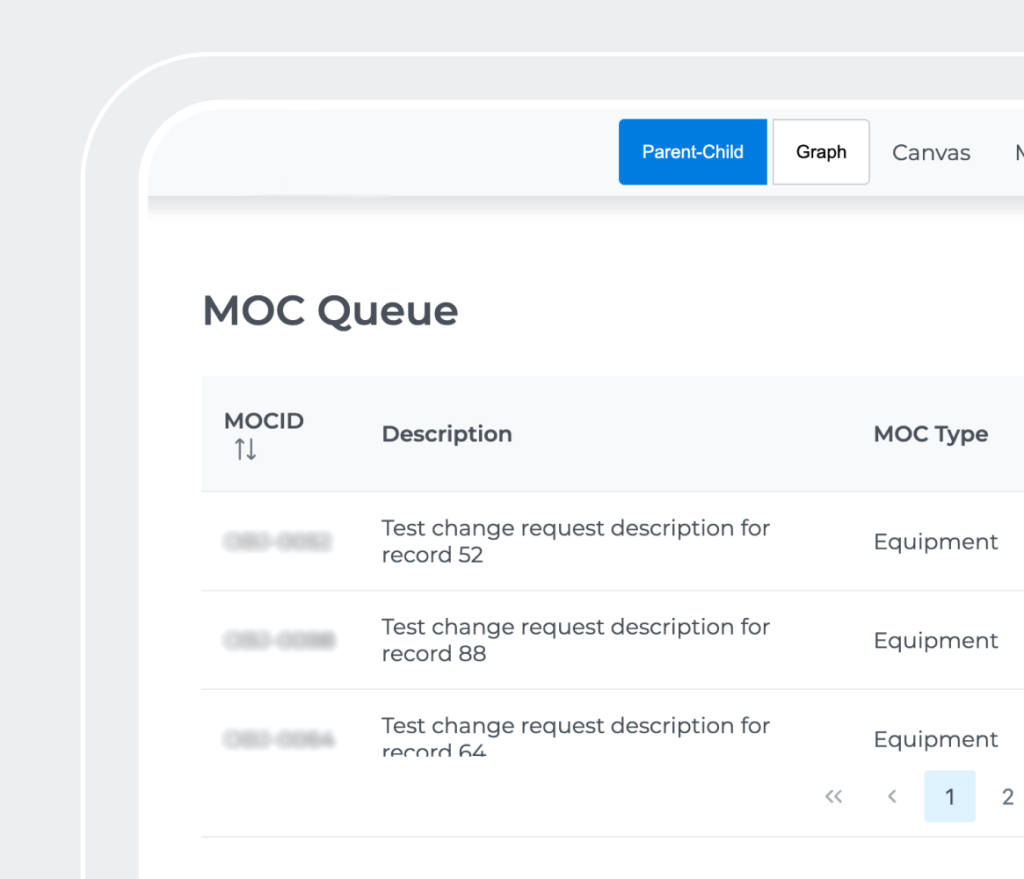
La solution finale est un Système intelligent de données de projet (Intelligent Project Data System) basé sur le web, conçu pour centraliser, structurer et gouverner des données de projet complexes. Il remplace des workflows fragmentés et fortement centrés sur les documents par une plateforme unifiée, orientée données, qui sert de source unique de vérité.
Le système s’intègre de manière transparente à l’écosystème d’entreprise existant du client:
- Microsoft Admin Center est utilisé pour la synchronisation des utilisateurs et la gestion des identifiants.
- SharePoint d’entreprise sert de référentiel documentaire et de couche de stockage.
- Un backend basé sur un graphe de connaissances garantit la cohérence, la traçabilité et la scalabilité des données de projet.
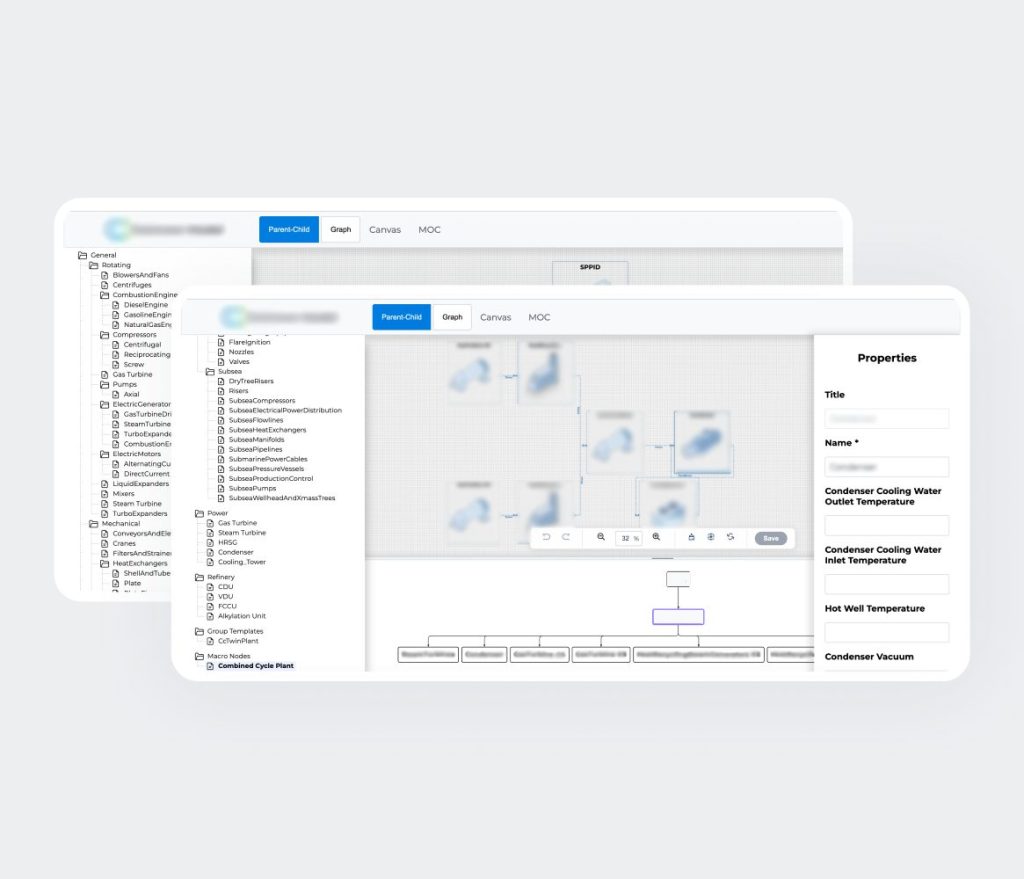
La plateforme permet aux chefs de projet, ingénieurs et spécialistes d’accéder à des informations techniques, financières et juridiques fiables et à jour, avec un niveau de détail adapté, afin de prendre des décisions plus rapides et plus sûres tout en réduisant le risque opérationnel.
La solution comprend les modules suivants:
1. Définition du modèle commun
Définit une ontologie canonique couvrant les entités clés, les attributs, les relations et les contraintes. Elle établit un langage de données partagé pour le métier tout en fournissant aux développeurs une base stable pour l’ingestion, la validation et l’évolution du système.
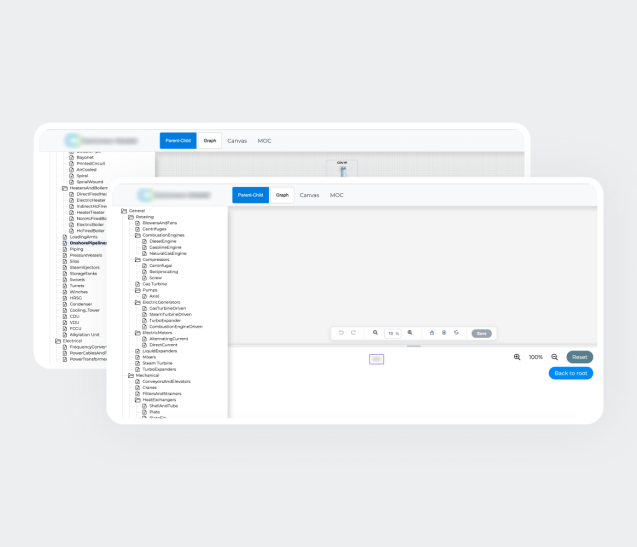
Définition du modèle commun
2. Registre du modèle et gestion des versions
Gère les versions de l’ontologie, suit la compatibilité des consommateurs et applique des règles de dépréciation. Cela permet une évolution sécurisée des modèles de données pour le métier et des changements de schéma contrôlés pour les équipes logicielles.
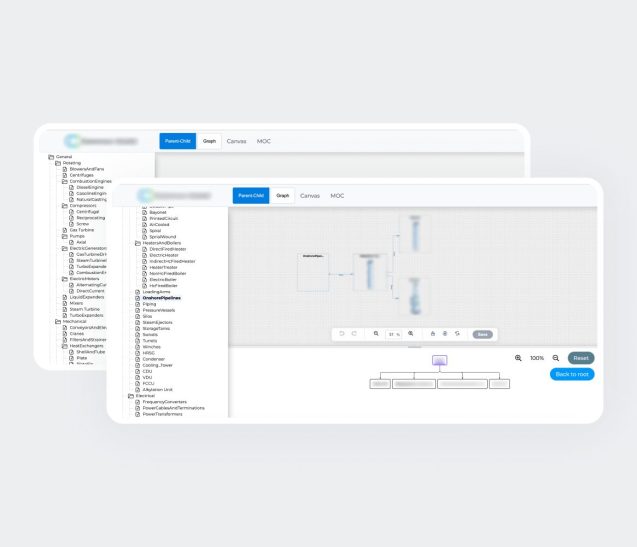
Registre du modèle et gestion des versions
3. Parseur / Ingestion
Mappe les données issues de plusieurs systèmes de référence (SOR) vers des instances du modèle commun, en assurant la normalisation et l’alignement sémantique. Il réduit l’effort manuel côté métier et découple les systèmes sources des structures de données internes pour les développeurs.
4. Moteur de validation et de règles
Applique des contraintes de schéma et une logique inter-entités afin d’assurer la cohérence des données. Cela renforce la confiance dans les données opérationnelles et fournit un mécanisme centralisé et maintenable d’application des règles.
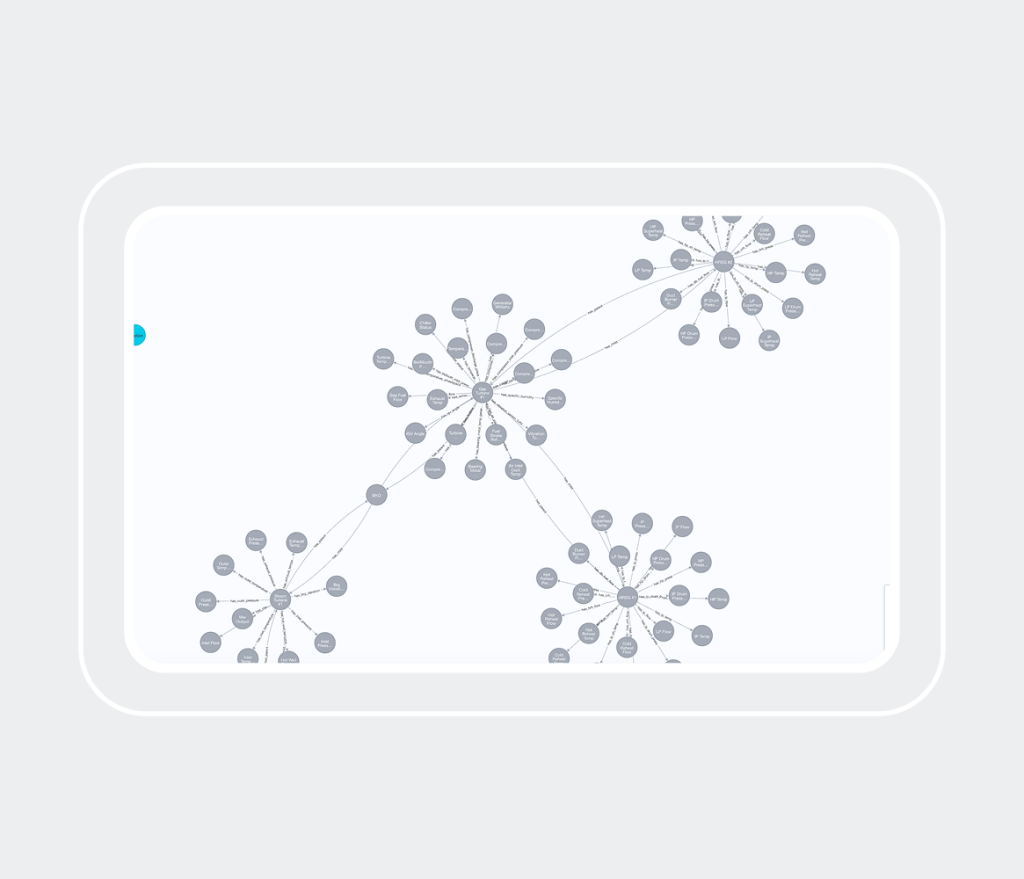
5. Stockage des instances (Neo4j)
Stocke les instances du modèle commun sous forme de graphe de connaissances, avec gestion de l’identité, de la provenance et des versions. Il sert de source unique de vérité pour le métier et prend en charge des requêtes efficaces riches en relations pour les développeurs.
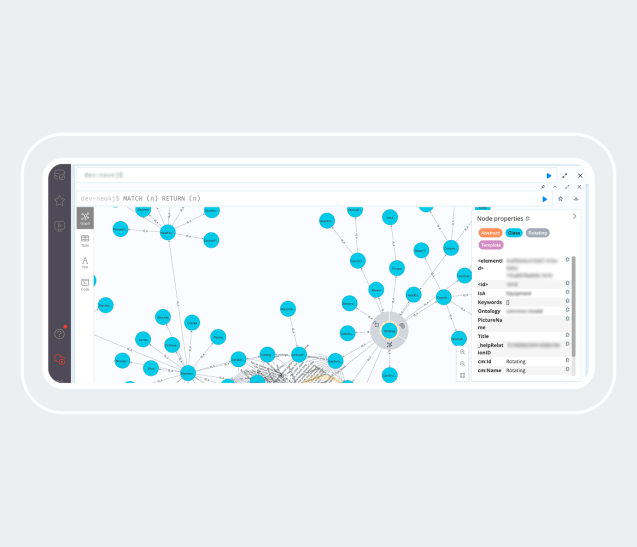
Stockage des instances (Neo4j)
6. Projection du graphe de connaissances
Crée des vues de graphe optimisées et adaptées à la consommation par le frontend. Cela simplifie l’exploration des données pour les utilisateurs tout en préservant une séparation claire entre les données cœur et les modèles UI.
7. Synchronisation et rapprochement
Détecte les changements, résout les conflits et maintient l’alignement des systèmes de référence avec le modèle commun. Il améliore la cohérence des données pour le métier et permet une logique de synchronisation déterministe pour les développeurs.
8. API / Couche d’accès
Fournit un accès sécurisé et contrôlé aux données pour des consommateurs internes et externes. Elle prend en charge l’intégration des systèmes côté métier et applique des règles d’accès et de validation au niveau technique.
9. Administration et outillage
Gère l’authentification, l’autorisation, la journalisation et le diagnostic. Il garantit une sécurité et une observabilité de niveau entreprise, tout en simplifiant l’exploitation et la maintenance du système.
Administration et outillage
Effets Commerciaux pour le Client
À la suite du projet, le client a obtenu un contrat avec son client final (une entreprise pétrolière et gazière), validant à la fois l’approche technique et la viabilité commerciale de la solution. L’application frontend livrée sert désormais de produit opérationnel que le client utilise activement pour démontrer le concept à d’autres prospects, soutenant ainsi ses efforts de développement commercial et de vente.
Une fois pleinement déployé, l’outil de validation Management of Change (MOC) devrait accélérer significativement le processus de clôture des MOC. Étant donné que les coûts rapportés par Chevron liés aux retards associés aux MOC s’élevaient à environ 8 millions de dollars l’année précédente, la solution a le potentiel de réduire de manière notable les temps d’arrêt des installations et les pertes financières associées, en améliorant la cohérence des données, la validation et la rapidité de prise de décision.
Au-delà de l’impact business direct, le projet a démontré la capacité du client à évoluer vers une offre orientée produit et centrée sur les données dans un environnement traditionnellement piloté par les documents, renforçant ainsi sa position concurrentielle à long terme.