




À propos du client
Le client est une société de services financiers basée au Luxembourg, opérant dans un environnement européen fortement réglementé. Dans le cadre de ses obligations réglementaires et de sa stratégie interne de sécurité, l’entreprise avait besoin de capacités centralisées de supervision de la sécurité et de détection des incidents.
L’organisation exploite une infrastructure réseau segmentée, composée de plusieurs sous-réseaux et groupes de serveurs. L’environnement comprend des serveurs Windows administrés via Active Directory, protégés par une infrastructure de pare-feu de niveau entreprise, des services VPN et des serveurs proxy. Ils comptent parmi nos clients privilégiés pour nos services de développement de logiciels financiers.
Compte tenu du contexte réglementaire en Europe et de l’augmentation des risques de cybersécurité, l’entreprise avait besoin d’une solution de développement SIEM (Security Information and Event Management) capable de collecter, traiter, analyser et corréler les données liées à la sécurité sur l’ensemble de l’infrastructure.
Défi métier
Le client avait besoin de services de mise en œuvre de SIEM afin de se conformer aux normes européennes de sécurité de l’information et aux exigences réglementaires.
Bien qu’un autre prestataire ait initialement installé Splunk, la configuration était basique et ne prenait pas pleinement en charge une supervision de sécurité avancée ni la détection automatisée des incidents, objectifs devant être atteints grâce au développement SIEM. Le système manquait d’une orchestration structurée des logs, d’une utilisation optimisée des licences et de scénarios de détection des menaces bien conçus.
Les principaux défis avant le développement SIEM étaient les suivants:
- Concevoir une ingestion centralisée des logs provenant de divers composants de l’infrastructure
- Filtrer et structurer les logs afin d’optimiser la consommation de licences Splunk
- Développer des scénarios de corrélation de sécurité pertinents
- Mettre en place des mécanismes automatisés de génération d’incidents
- Établir une base évolutive pour étendre la couverture des menaces
- Obtenir des résultats malgré des contraintes de ressources
Le client ne disposait pas non plus d’un spécialiste dédié aux services de mise en œuvre de SIEM, ce qui rendait indispensable la prise en main en autonomie ainsi que la prise de décisions d’architecture.
Processus
Il n’existe pas de séparation stricte entre les différentes composantes des services de développement logiciel sur mesure, mais nous pouvons globalement distinguer 6 étapes de participation au processus.
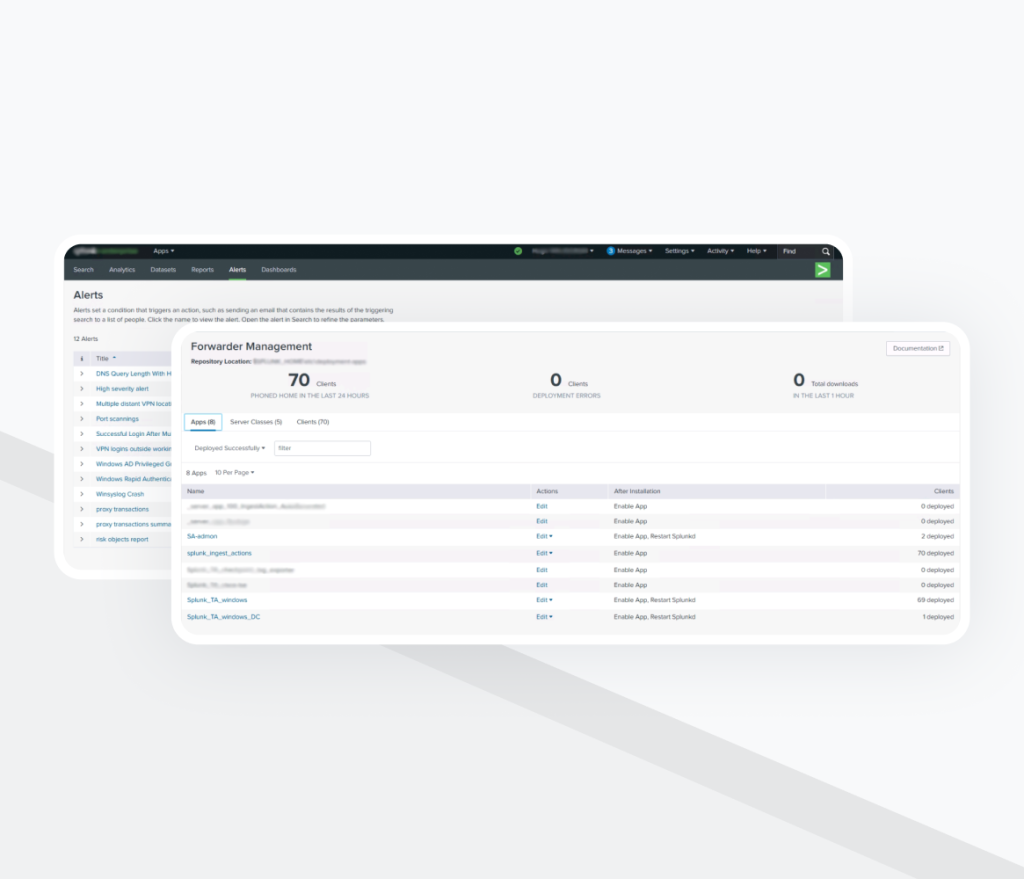
Étape 1: Évaluation de l’infrastructure et optimisation des licences
Les services de mise en œuvre de SIEM ont commencé par un audit complet de l’environnement Splunk existant et de l’architecture de l’infrastructure.
Les principales activités comprenaient:
- Identifier toutes les sources de logs disponibles
- Analyser la configuration existante des forwarders
- Évaluer la consommation de licences
- Réorganiser l’administration afin d’assurer un contrôle centralisé des configurations
L’accent a été mis sur la détermination des données de logs réellement utiles pour la supervision de la sécurité, et de celles pouvant être filtrées afin de réduire l’utilisation des licences sans compromettre la visibilité.
Étape 2: Intégration des sources de logs et modélisation des données
Toutes les sources de données disponibles ont été intégrées au système de mise en œuvre du SIEM:
- Journaux d’événements Windows
- Événements Active Directory
- Logs DNS
- Logs de pare-feu
- Logs VPN
- Logs proxy
- Activité des comptes OpenPassword
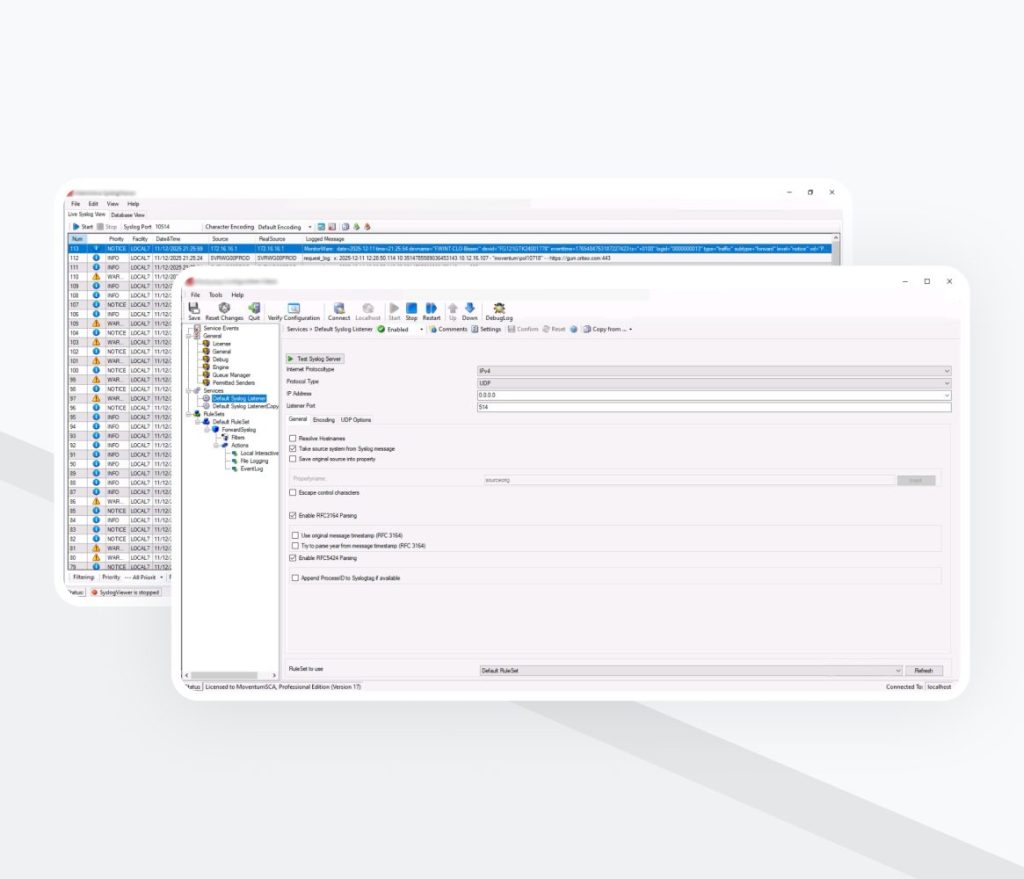
Les serveurs Windows envoyaient les logs via des Splunk forwarders directement au serveur SIEM. Les logs du pare-feu, du VPN et du proxy étaient acheminés vers un serveur syslog, stockés sous forme de fichiers, puis traités par un forwarder.
Au cours de cette phase de développement SIEM:
- Les données ont été structurées dans des index distincts
- Des extractions de champs ont été configurées
- Les modèles de données ont été harmonisés
- Le parsing et la normalisation ont été optimisés
Le volume d’ingestion quotidien a atteint 8 à 10 Go, avec un stockage total des index dépassant 300 Go.
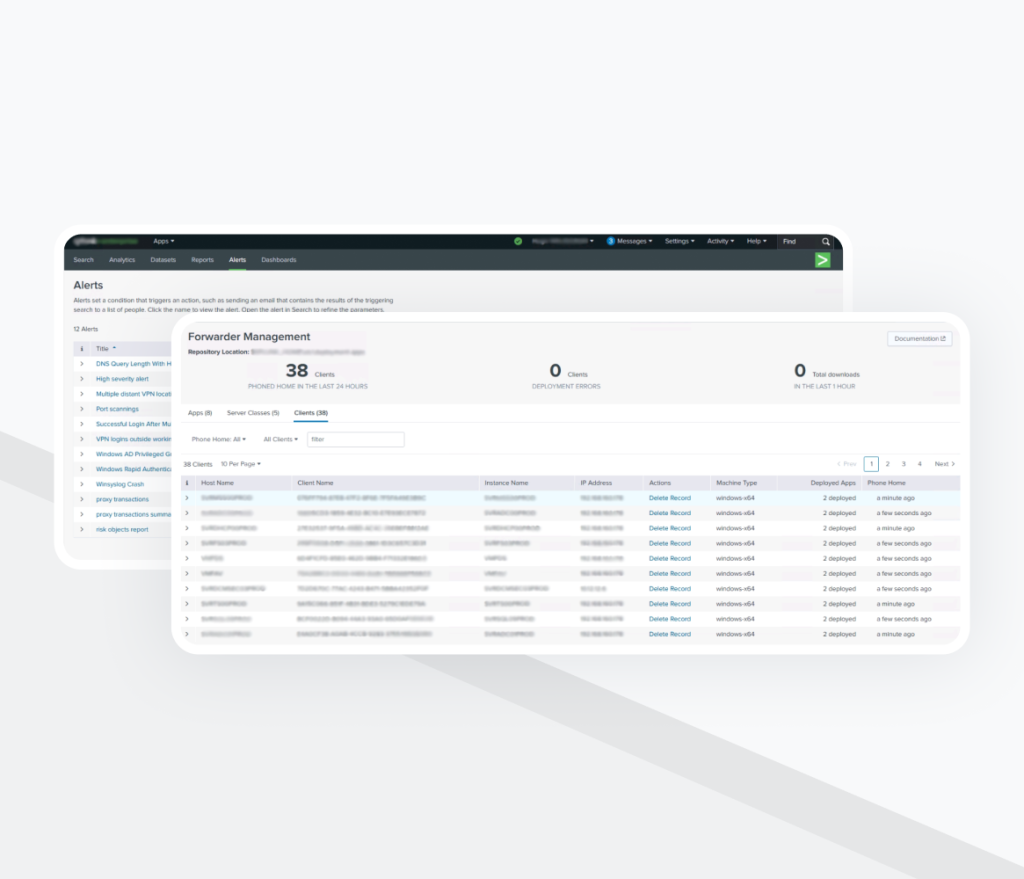
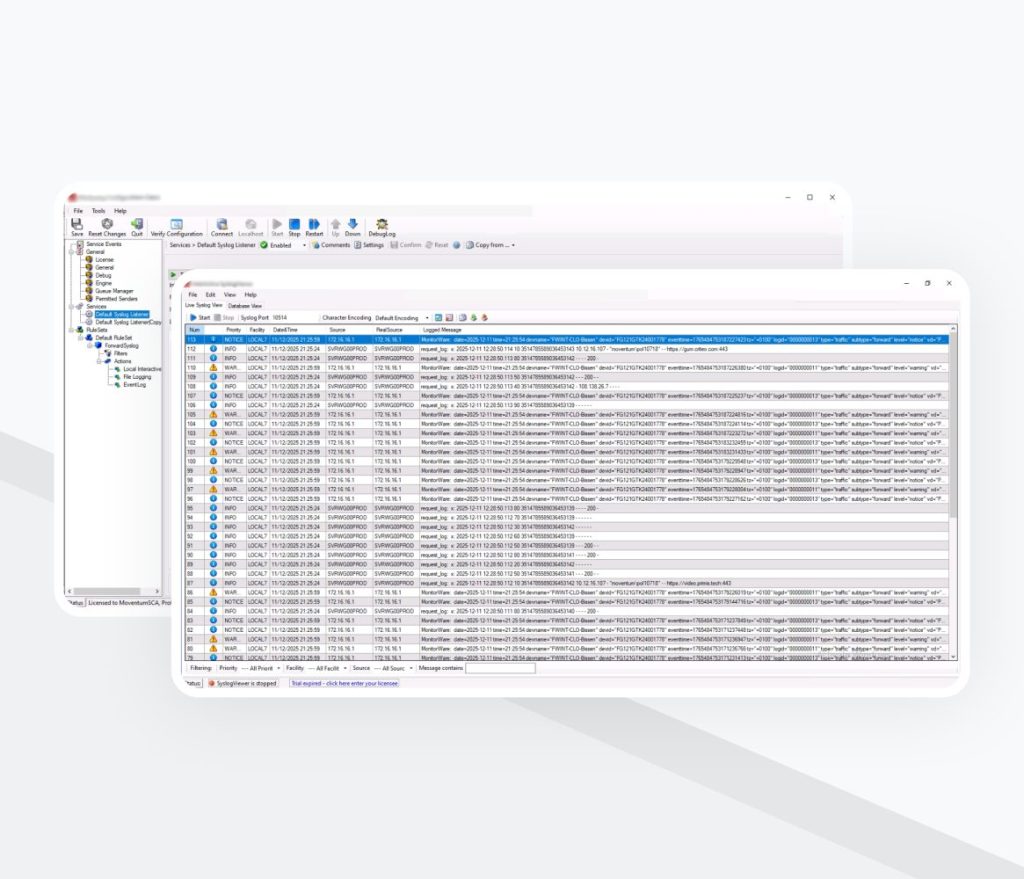
Étape 3: Développement de tableaux de bord
Les services de mise en œuvre de SIEM comprenaient la création de tableaux de bord. Ces tableaux de bord ont été conçus pour offrir une visibilité structurée sur:
- Les flux de trafic réseau
- L’activité VPN
- L’utilisation du proxy
- Les événements de pare-feu
- Les tendances de détection des menaces
Ils permettaient aux ingénieurs sécurité de naviguer rapidement dans les données et de mener des investigations de manière efficace.
Étape 4: Développement des recherches de corrélation
Sur la base des sources de données disponibles, des scénarios de sécurité pertinents ont été identifiés et conçus.
Pour chaque scénario:
- Des recherches de corrélation ont été développées
- Une logique de seuils a été définie
- Les faux positifs ont été minimisés
- Des tests manuels ont été menés à partir de données historiques et via le déclenchement contrôlé d’événements
L’objectif était d’assurer la création automatique d’incidents en cas d’activité suspecte.
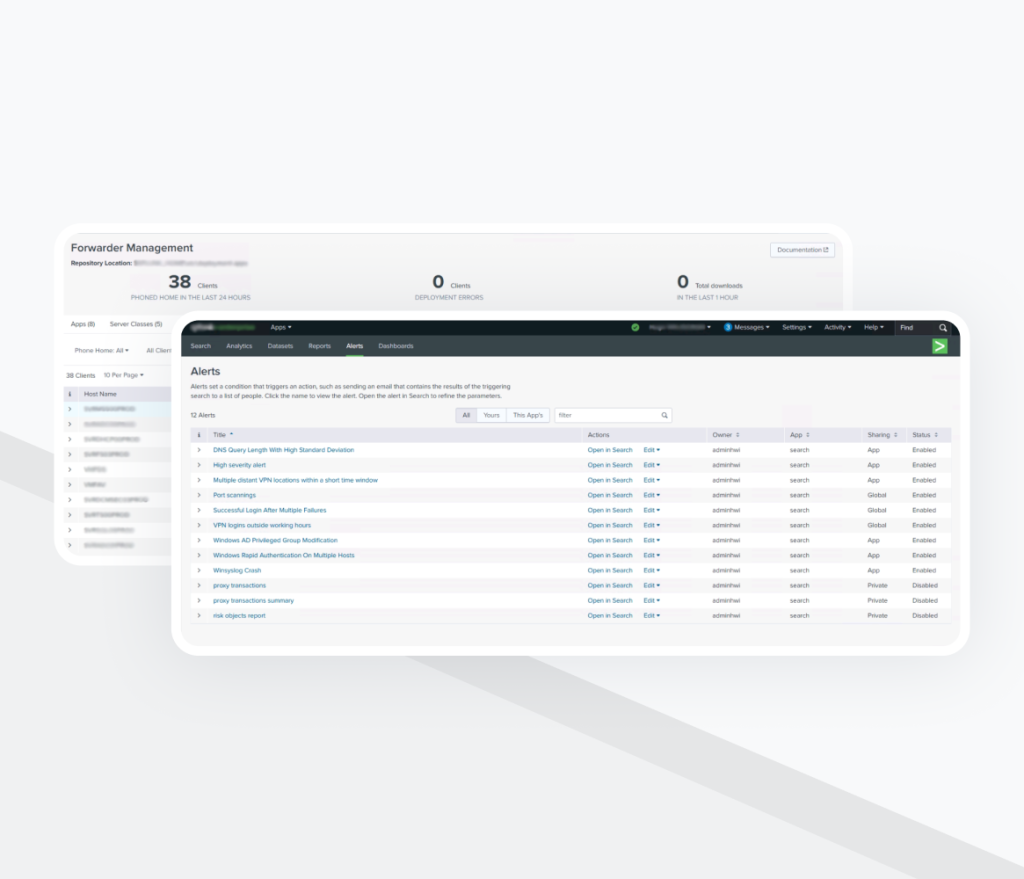
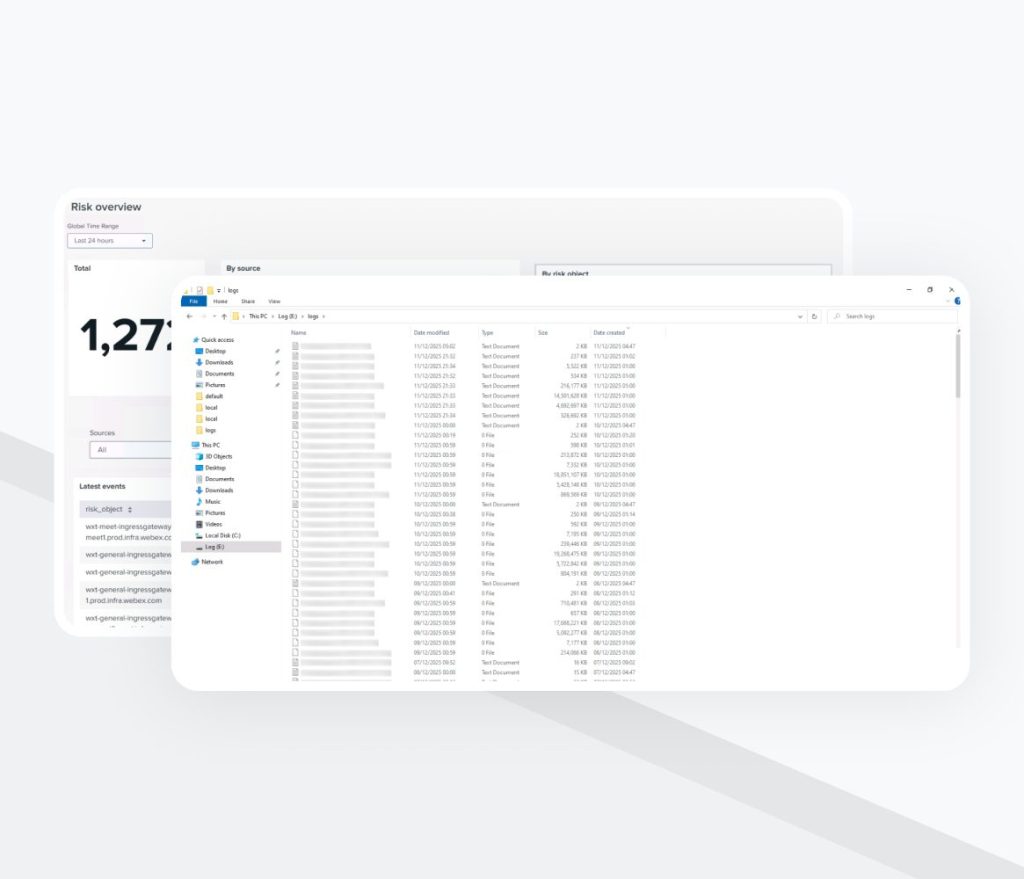
Étape 5: Index d’incidents centralisé et alerting
Toutes les détections déclenchées ont été agrégées dans un index de corrélation dédié. Cela a permis:
- Un point d’investigation unique
- Un suivi structuré des incidents de sécurité
- De meilleures performances de recherche
- Une meilleure visibilité pour la supervision
En outre, dans le cadre du développement SIEM, la création dynamique de tickets Jira a été mise en place afin de générer automatiquement des incidents pour les ingénieurs sécurité.
Étape 6: Optimisation continue et montée en charge (développement SIEM en cours)
En raison de contraintes de ressources au niveau de l’infrastructure, une optimisation constante était nécessaire:
- Affinage itératif des requêtes
- Améliorations du filtrage des événements
- Suivi de l’utilisation des licences
- Optimisation des performances
Le système évolue en continu afin d’étendre la couverture des menaces et d’améliorer la qualité de détection.
Aperçu du produit final

VPN
Le résultat de nos services de développement web est une plateforme SIEM centralisée (après l’assurance qualité et des services de tests logiciels) basée sur Splunk Enterprise, qui:
- collecte des logs provenant de composants d’infrastructure distribués;
- normalise et structure les données de sécurité;
- corrèle les événements à partir de multiples sources;
- génère automatiquement des incidents de sécurité;
- s’intègre à Jira pour la gestion des incidents;
- fournit des tableaux de bord pour une visibilité opérationnelle.
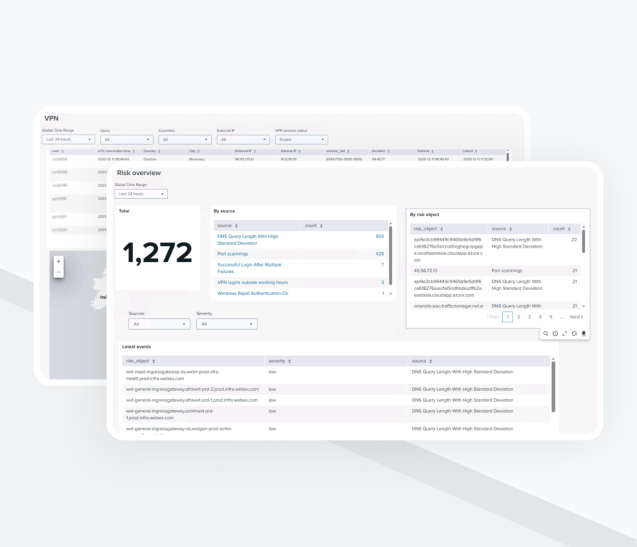
Vue d’ensemble des risques
Le système traite 8 à 10 Go de données de sécurité par jour et conserve plus de 300 Go de données historiques indexées.
Effets métier pour le client
- Supervision centralisée de 100 % des composants critiques de l’infrastructure (serveurs Windows, AD, pare-feu, VPN, proxy, DNS).
- Traitement de 8 à 10 Go de logs par jour, avec plus de 300 Go de données historiques indexées pour les investigations et les audits.
- Recherches de corrélation automatisées couvrant les principaux scénarios de sécurité (abus d’authentification, anomalies réseau, activités à privilèges).
- Réduction de 60 à 70 % du traitement manuel des incidents grâce à la création automatique de tickets Jira.
- Amélioration de la détection des incidents: passage d’une revue manuelle (heures) à des alertes quasi en temps réel (minutes).
- Optimisation de 20 à 30 % de l’utilisation des licences Splunk grâce au filtrage et à la priorisation des logs.
- Mise en place d’un processus de supervision traçable et auditable, aligné sur les normes de sécurité européennes.
- Construction d’une base SIEM évolutive permettant l’extension progressive de la couverture de détection des menaces.